Einer von mir gern gehörten Podcasts ist Logbuch Netzpolitik und ich finde den Inhalt so wichtig, daß ich gerne eine Niederschrift (Transkript) der Gespräche hätte - das erhöht die Findbarkeit mit Suchmaschinen enorm.
2015 machte ich schon mal einen Versuch, einzelne Folgen per Crowdsourcing über einen inzwischen nicht mehr verfügbaren Webdienst zu transkribieren, allerdings fanden sich nicht genug Leute - es wurde nicht mal eine Folge fertig.
Das Thema ließ mich nicht los, und vor zwei Monaten beschäftigte ich mich wieder mal damit. Schnell war klar, daß ich es diesmal mit technischer Unterstützung angehen wollte, da Spracherkennung ja inzwischen verbreitet ist.
Sprache zu Text
Zur Texterkennung probierte ich Google Cloud Speech für 0.6ct pro Minute, was allerdings kein Problem war, weil man beim initialen Anmelden 300US$ Guthaben bekommt.
Ich schaute mir einige Tools an (transcribe_audio, podcast-transcriber, transcribe-podcast) und bastelte mir dann ein eigenes Script.
Die LNP-Folgen liegen als .opus-Datei vor, und Google Cloud Speech unterstützt laut Dokumentation dieses Format .. allerdings klappte es bei 4 Versuchen nicht. Der Support meinte, die Opus-Unterstützung ist noch experimentell.
Ich konvertierte die 25MiB .opus-Datei in eine 500MiB .flac-Datei (mono!) und lud diese hoch. Einige Stunden später hatte ich eine JSON-Datei mit Wörtern und deren zeitlicher Position. Ein Beispiel:
.. { "alternatives": [ { "transcript": " ja mit vier patentierten ja okay deswegen die Grünen auch mit 3,8 ist nicht mehr schaffen werden und auch wenn es noch eine Schwankungsbreite von 0,2% gibt es ist wie gesagt ich habe dich so gut wie ausgeschlossen das da jetzt noch der Einzug geschafft wird und die ca 120 Mitarbeiter der grüne Bundespartei wurden auch schon beim Arbeitsmarktservice angemeldete spricht hier werden jetzt schon am Rückzug und Anna man Abwicklung dieser Bundes Parteien die auch nach dem letzten Mal kämpfen dir auch so lange gedauert haben noch auf einem Riesenberg Schulden steckt sitzt uns da ist schon viel Zucker verloren gegangen die Grünen waren definitiv einer der kommt doch tiefsten Kräfte im österreichischen Parlament Tourismus und haben sie aber aufgrund einer Verkettung von wirklich ja für sie sehr negativen Ereignissen nicht", "confidence": 0.9379103, "words": [ { "startTime": "444.500s", "endTime": "445.100s", "word": "ja" }, { "startTime": "445.100s", "endTime": "445.200s", "word": "mit" }, { "startTime": "445.200s", "endTime": "445.400s", "word": "vier" }, ..
Es gibt mehrere Probleme:
- Keine Satzenden.
- Keine Sprechersegmentierung. Der von unterschiedlichen Personen gesprochene Text ist ein einziger großer Block.
- Fehlerhafte Erkennung. Bei Standardwörtern ist die Erkennung ok, aber es gibt Wörter wie "Netzpolitik", die immer falsch erkannt wurden. Manchmal waren komplette Sätze falsch.
- Das Transkript ist Wort-für-Wort, d.h. mit Verzögerungslauten wie "ähm" und Wortwiederholungen. Das liest sich nicht gut.
Insgesamt war das ganze aber immer noch besser als alles selbst tippen zu müssen. "Nur" korrigieren :)
Sprechersegmentierung
Das manuelle Aufteilen der Sätze auf verschiedene Sprecher wollte ich auch nicht machen. Auf meiner Suche fand ich spokendata.com, die zwar kein Deutsch unterstützen, dafür aber eine ziemlich brauchbare Sprechererkennung ("Diarization") haben (und das kostenlos!).
Man kann ihnen im Webinterface die URL zur .opus-Datei hinwerfen und bekommt eine Stunde später eine Mail, daß die XML-Datei fertig ist.
Zwar wurden bei der LNP-Folge 232 (die 2 Sprecher hat) insgesamt 38 Sprecher erkant, allerdings konnte ich das mit dem Transkriptionsprogramm transcriber ziemlich schnell auf 2 reduzieren. Man kann dort Sprecher komplett ersetzen.
<?xml version="1.0" encoding="utf-8"?> <data> <segment> <start>0.47</start> <end>2.05</end> <speaker>A</speaker> <text></text> </segment> <segment> <start>2.55</start> <end>3.44</end> <speaker>F</speaker> <text></text> </segment> <segment> <start>3.77</start> <end>8.68</end> <speaker>H</speaker> <text></text> </segment> ...
Zusammenführen
Jetzt hatte ich den Text in der .json-Datei von Google, und die Sprechersegmentierung in der XML-Datei. Als Entwickler bastelte ich mir ein kleines Script, welches die beiden kombiniert.
Die besten Ergebnisse bekam ich bei der Nutzung der Wortendezeiten.
Transcriber
Auf meinem Laptop läuft aus Angst-vor-dem-Update-Gründen noch Ubuntu 14.04, und dort gibt es ein nutzbares Audiotranskriptionsprogramm: transcriber. Es ist ziemlich alt (TCL/TK!), aber doch brauchbar.
Nach der Konvertierung der Audiodatei in .wav und dem Schreiben eines Konvertierungsscripts von dem segmentierten XML in das von transcriber unterstützte .trs-Format konnte ich endlich anfangen.
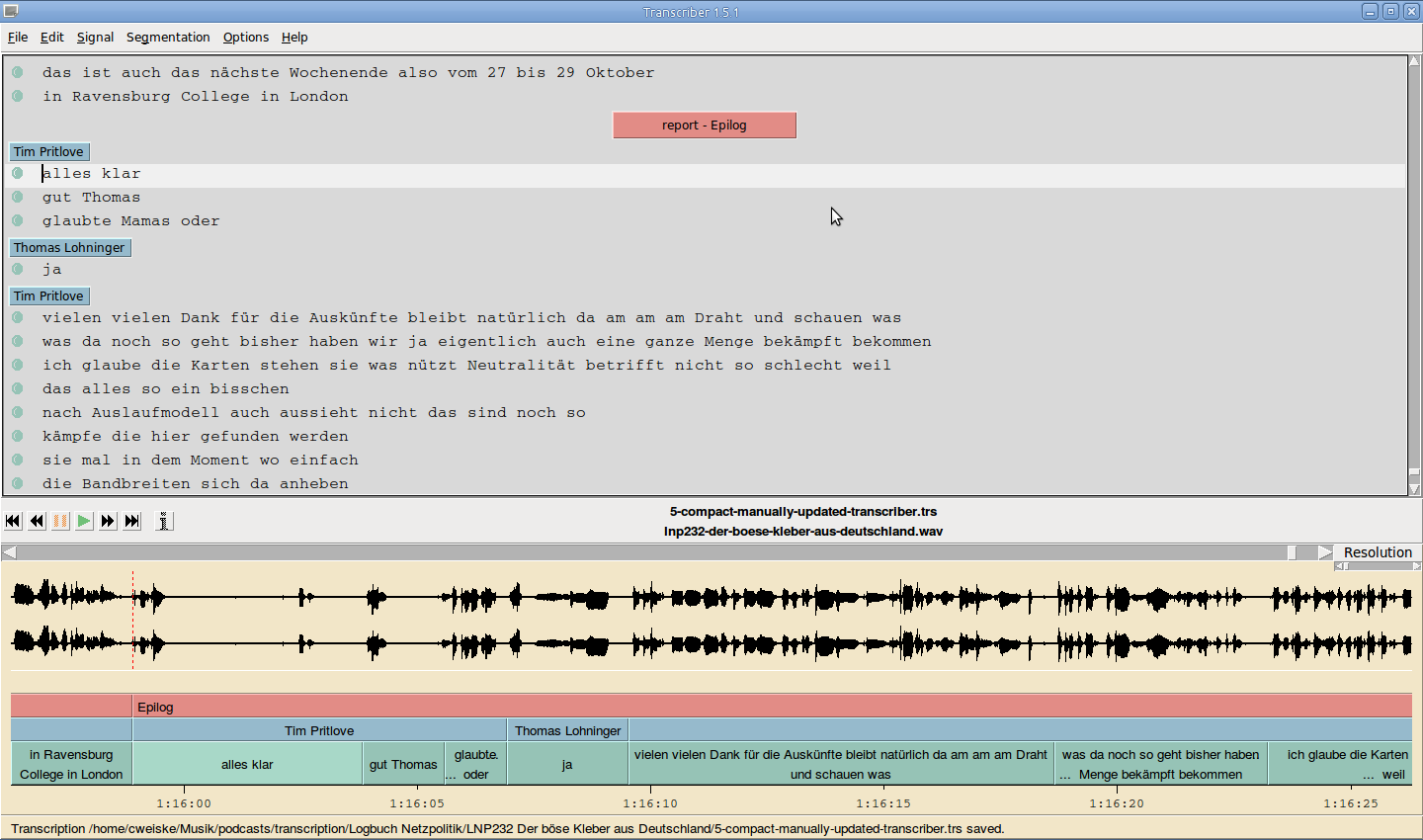
Zwischendurch merkte ich, daß transcriber noch Leerstellen einfügt wenn die aufeinanderfolgenden Segmente zeitlich nicht auf die Millisekunde passen. Weiter gab es durch die Sprecherreduzierung viele aufeinanderfolgende Segmente, die denselben Sprecher hatten. Um das nicht alles manuell im Programm beheben zu müssen baute ich noch ein Script, was .trs-Dateien kompakt macht.
LNP Folge 232 war 1h17m lang, und ich brauchte für die reine Korrektur des kompakten Transcripts um die 3h, ein Verhältnis von etwa 2:1.
HTML
Zum Schluss soll das ganze noch ins Netz, also brauchte ich das ganze als .html-Datei.. Ja, wieder ein Script, aber diesmal kein PHP sondern XSL: trs2html.xsl.
Im HTML wird ein Audioplayer eingebunden, und man kann per Abspielknopf vor jedem Satz zu exakt dieser Stelle im Podcast springen!
Das Ergebnis könnt ihr hier sehen:
Transkript von Logbuch Netzpolitik #232: Der böse Kleber aus Deutschland.
Links
Bei meiner Recherche bin ich auf einige interessante Blogposts, Dienste und Tools gestoßen. Hier unkommentiert die Linkliste:
Speech Recognition Services
Transcription services
- spokendata.com
- deepgram.com
-
speechlogger
- play podcast in media player, use pavucontrol to change record source of browser to media player
- takes as long as the podcast.
- no newlines..
- swiftscribe
Blogposts
- Semi-automated podcast transcription
- Comparing Transcriptions
- Note to Self: Transcribing Podcasts
- Native HTML5 captions and titles for audio content with WebVTT
- Podcast Transcription with Watson
Formats
- W3C: A transcript extension for HTML
- W3C: WebVTT: The Web Video Text Tracks Format
- Matroska WebVTT spec
Examples
- Gretta: The Art And Science Of Comedy
- This Week in the IndieWeb Audio Edition • October 14th - 20th, 2017
Code
- transcribe_audio (see blogpost, works offline!), multiple clouds, hardcoded filename/language
- podcast-transcriber (google cloud)
- transcribe-podcast - (google cloud)
- http://otranscribe.com/ - web app to manually transcribe audio
- video-transcriber - webapp to transcribe
- cweiske podcast-transcriptions - my own things