Some time ago I published results of benchmarks I did for my diploma thesis. Since then I had Virtuoso put on my list of competitors; further I added three new queries that are not as artificial as the previous ones as they try to resemble queries used in the wild.
The competitors compared are:
- RAP's old SparqlEngine
- RAP's new SparqlEngineDb I wrote as part of my thesis
- ARC, another PHP implementation made for performance (2006-10-24)
- Jena SDB, a semantic web framework written in Java (beta 1)
- Redland, a C implementation. (1.0.6)
- Virtuoso Open Source Edition 5.0.1
The tests have been run on a Athlon XP 1700+ with 1GiB of RAM. Both PHP and Java have been assigned 768MiB of RAM. MySQL in version 5.0.38 on a current Gentoo Linux has been used with PHP 5.2.3 and Java 1.5.0_11. All the libraries except Virtuoso support MySQL as storage, so this was used as backend.
I used the data generator of the Lehigh University Benchmark to get 200.000 RDF triples. Those triples were imported into a fresh MySQL database using the libraries' native tools.
To cut out times for loading the classes or parsing the php files, I created a script that included all the necessary files first and executed the queries ten times in a row against the lib. Taking the time between begin and return of the query function in milliseconds, I executed all queries against different database sizes: From 200.000, 100.000, 50.000, ... down to 5. All result data have been put into some nice diagrams.
Library notes
Jena needed some special care since the first run was always slow, probably because the JVM needed to load all the classes in the run. So Jena got a dry run and ten of which the times were taken afterwards.
ARC didn't like the ?o2 != ?o1 part and threw an error. The complex queries resulted in a "false" value returned after some milliseconds. I assume that something failed internally.
Redland has been used through its PHP bindings. While this seems to make it slower, I found out that it seems to have a bug in librdf_free_query_results() that causes delays up to 10 seconds depending on the dataset size. In my benchmark script, I did not call this method in order to give the lib some chance against the others. If I would have freed the results after each query, librdf would be second last.
Since I did not get the ODBC drivers working correctly, I used the isql program delivered with Virtuoso to benchmark the server. Virtuoso also had a bug in regex handling, so I have no timings for those queries.
Results
 The first set of SPARQL queries were chosen to be data independent
and concentrate on a single SPARQL feature only.
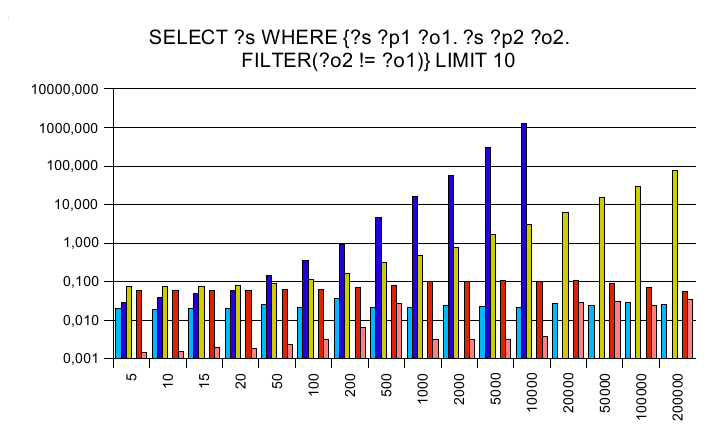
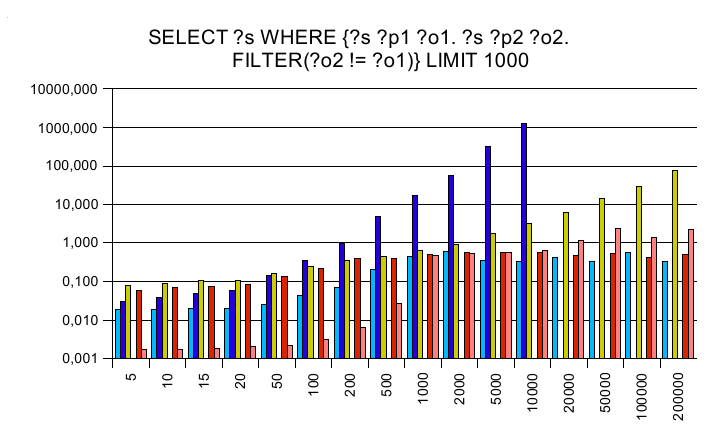
Three additional queries have been created to see how the engines
act on complex queries found in the real world outside.
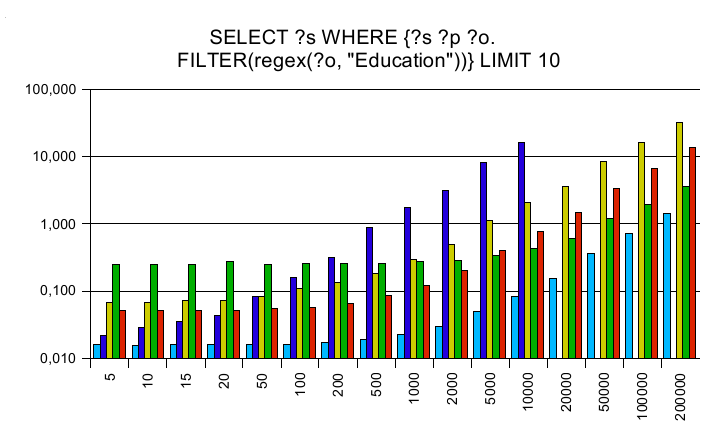
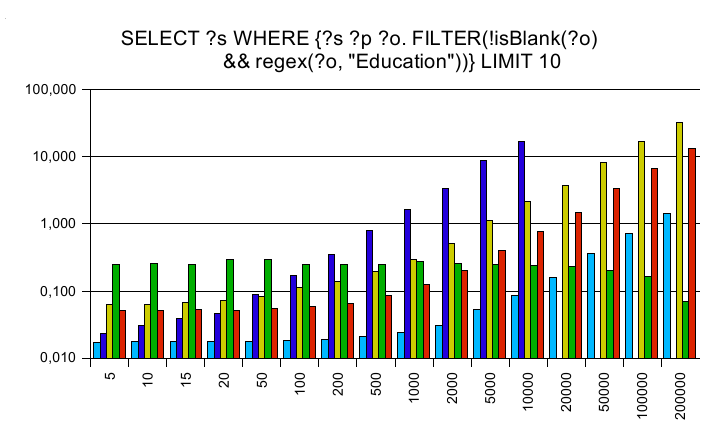
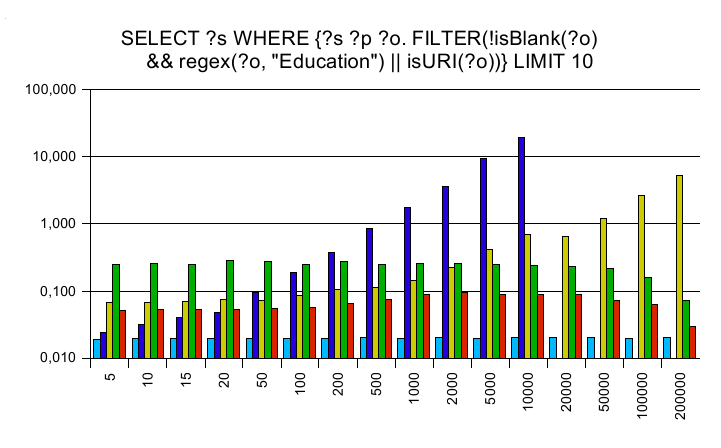
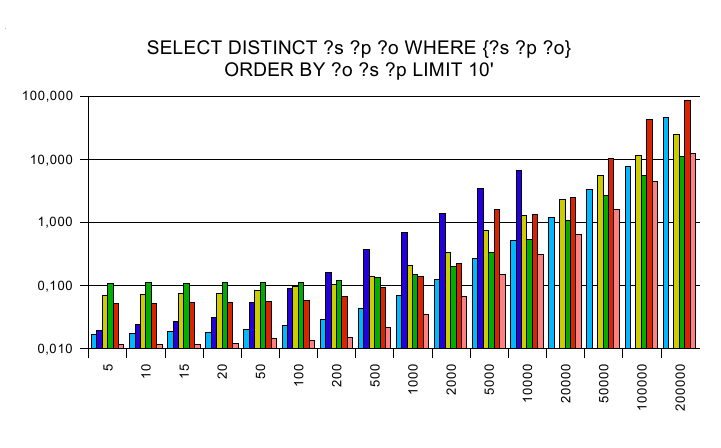
The y axis is a logarithmic scaled time axis in seconds, x displays
the number of records in the database.
The first set of SPARQL queries were chosen to be data independent
and concentrate on a single SPARQL feature only.
Three additional queries have been created to see how the engines
act on complex queries found in the real world outside.
The y axis is a logarithmic scaled time axis in seconds, x displays
the number of records in the database.
SELECT
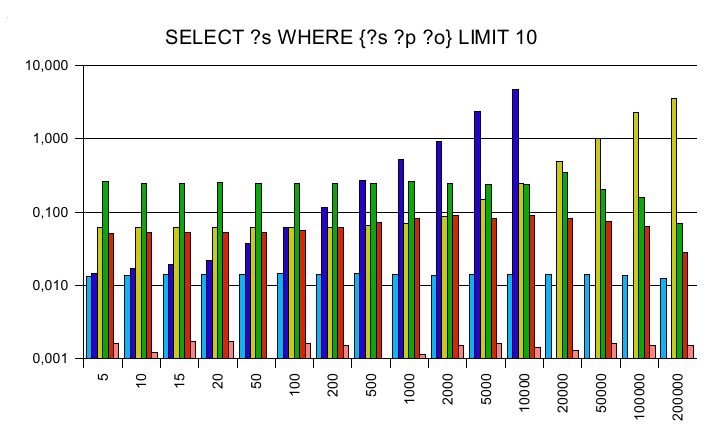
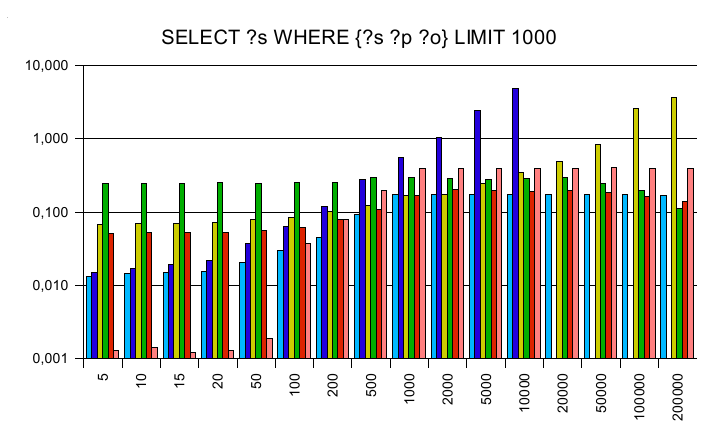
Cross joining all triples
Regular expressions
ORDER BY
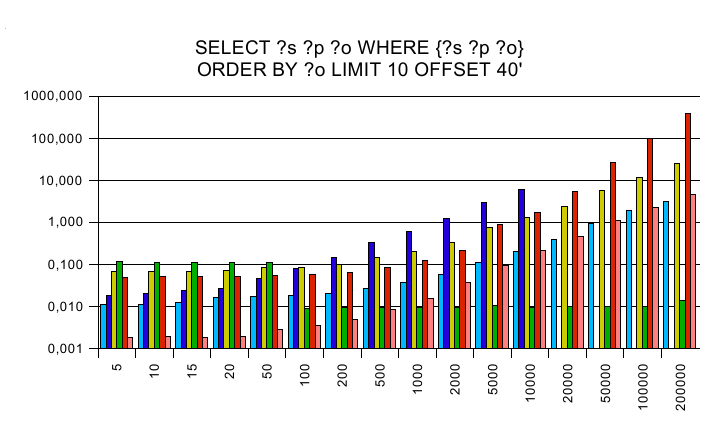
Complex queries
-
7 connected triples
PREFIX test:
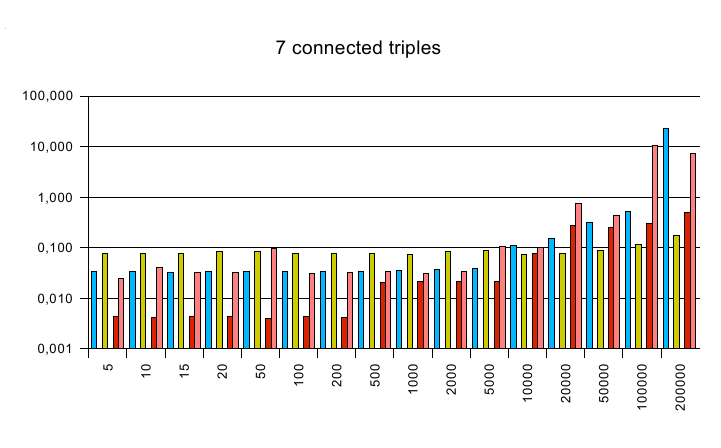
-
OPTIONAL
PREFIX test:
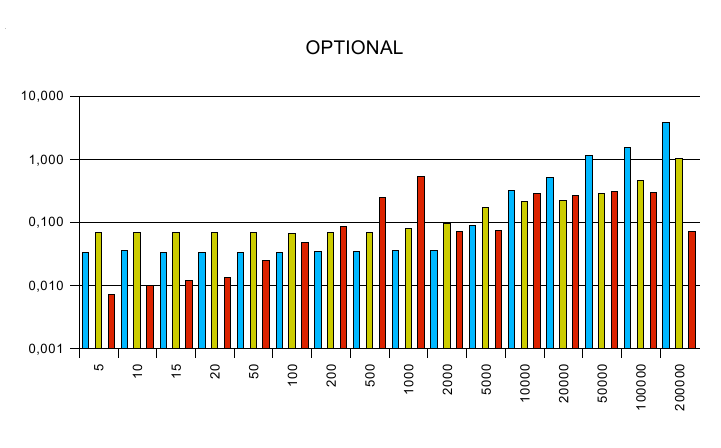
-
UNION
PREFIX test:
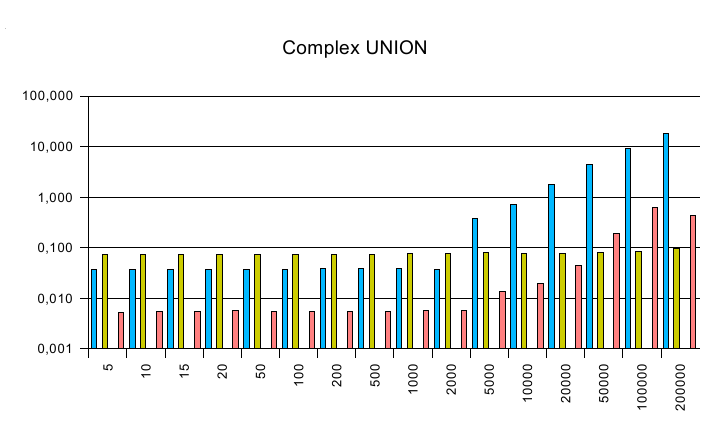
Average timings
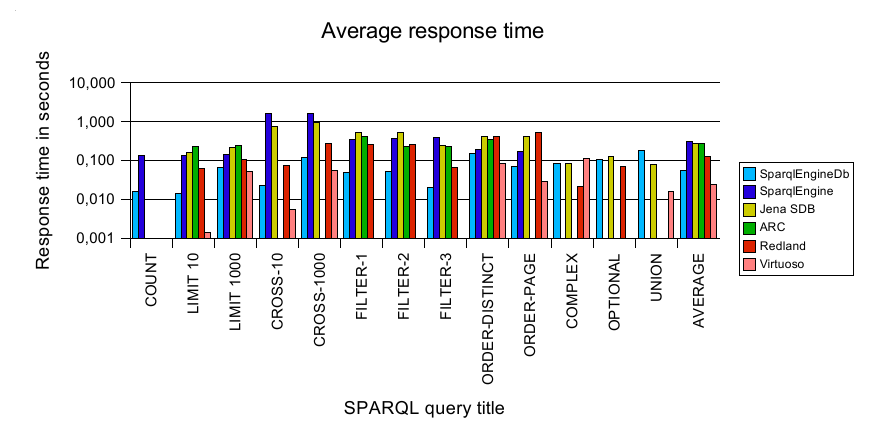
Conclusion
Jena has been the only engine beside SparqlEngineDb that executed all queries. ARC is not as fast as expected, and failed on nearly half of the queries. Redland is reasonable fast, although I expected it to gain more performance given that it is written in plain C. Virtuoso as the only commercially developed product is the fastest of all engines. But here and there, other engines have been faster which is nice to see :) And my SparqlEngineDb - I think it's pretty good, although the benchmark has shown enough points at which it can be made better and faster.