For my diploma thesis I ran some benchmarks to compare my SparqlEngineDb implementation to some other implementations. The competitors were:
- RAP's old SparqlEngine
- ARC, another PHP implementation made for performance (2006-10-24)
- Jena SDB, a semantic web framework written in Java (alpha 2)
- Redland, a C implementation. (1.0.6)
The tests have been run on a Athlon XP 1700+ with 1GiB of RAM. Both PHP and Java have been assigned 768MiB of RAM. MySQL in version 5.0.38 on a current Gentoo Linux has been used with PHP 5.2.2 and Java 1.5.0_11. All the libraries support MySQL as storage so this was used as backend.
Without going into the same details as I did for my thesis, some more information:
I used the data generator of the Lehigh University Benchmark to get 200.000 RDF triples. Those triples were imported into a fresh MySQL database using the libraries' native tools.
To cut out times for loading the classes or parsing the php files, I created a script that included all the necessary files first and executed the queries ten times in a row against the lib. Taking the time between begin and return of the query function in milliseconds, I executed all queries against different database sizes: From 200.000, 100.000, 50.000, ... down to 5. All result data have been put into some nice diagrams.
Library notes
Jena needed some special care since the first run was always slow, probably because the JVM needed to load all the classes in the run. So Jena got a dry run and ten of which the times were taken afterwards.
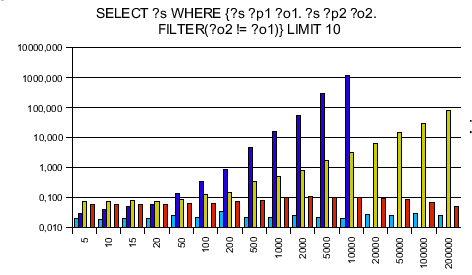
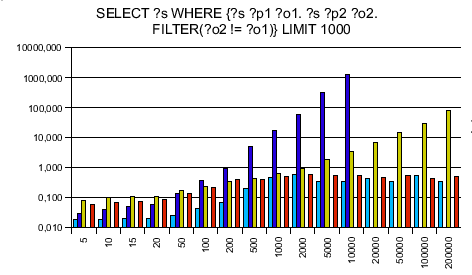
ARC didn't like the ?o2 != ?o1 part and threw an error.
Redland has been used through its PHP bindings. While this seems to make it slower, I found out that it seems to have a bug in librdf_free_query_results() that causes delays up to 10 seconds depending on the dataset size. In my benchmark script, I did not call this method in order to give the lib some chance against the others. If I would have freed the results after each query, librdf would be second last.
Results
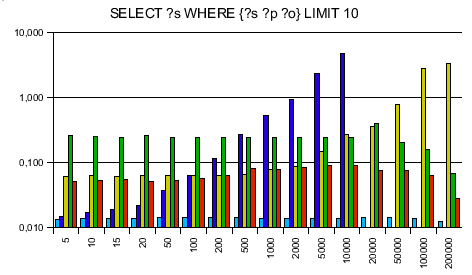
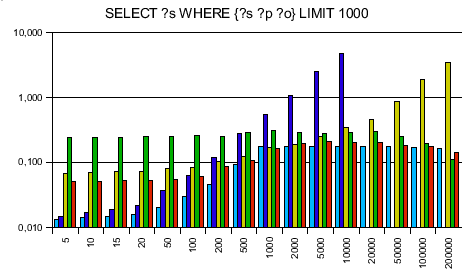
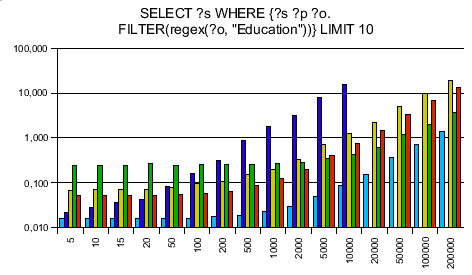
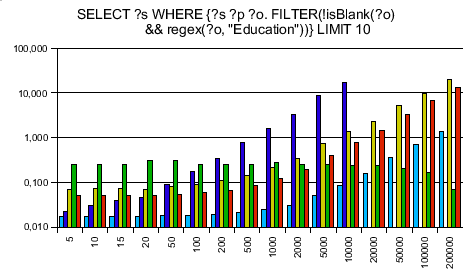
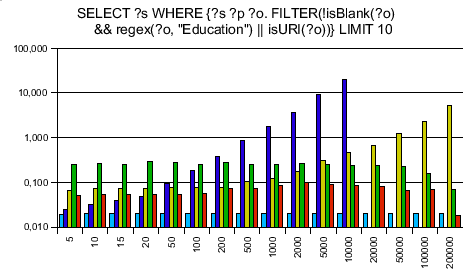
Testing RAP's old engine and Jena only first, I was surprised to see that my engine is on average 10 times faster then Jena and 14 times faster than RAP's SparqlEngine. Seeing that I can take the competition I ran tests against ARC and Redland - and was surprised again. ARC said of itself that it is made for speed, using PHP arrays instead of objects. Reading this I took it for granted that my engine can't be faster. Next, Redland is completely written in C making it extremely fast - no chance for my lib to win against. The more I wondered to get a speedup of 7.7 against ARC and 3.3 against Redland!
The SPARQL queries were chosen to be data independent. The y axis is a logarithmic scaled time axis in seconds, x displays the number of records in the database.
Here are the diagrams:
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
As always with benchmarks, take them with a grain of salt. Don't believe any benchmarks you didn't fake yourself. With different queries, it might be that different results turn up. You see that Jena is even a bit better at this one simplest query when my engine needs to instantiate 1000 results - creating objects in PHP is slow, so this is the point your benchmarks can make SparqlEngineDb look slow.