Dieser Artikel wurde ursprünglich im Blog meines Arbeitgebers veröffentlicht: Setup unserer Intranetsuchmaschine @ netresearch .
Während unserer täglichen Arbeit nutzen wir eine große Anzahl an Werkzeugen, in denen Informationen zu Projekten und Abläufen abgelegt werden.
Dazu gehören der Bugtracker JIRA, das Wiki, die Lesezeichenverwaltung, das interne Blog, unser zentrales LDAP-Adressbuch, der Git-Server, unser Pastebin, Logs der Chaträume und nicht zuletzt unser Projektnetzlaufwerk mit allen Dateien, die mit dem jeweiligen Projekt zu tun haben (Anforderungen, Designs, Schnittstellenbeschreibungen).
Zu viele Anlaufstellen, um die gesuchte Information manuell auf Anhieb zu finden. Aus diesem Grund begannen wir vor 2 Jahren mit dem Aufsetzen einer Intranetsuchmaschine. Ziel war es, alle Daten auf einmal durchsuchen zu können.
In diesem Blogartikel dokumentieren wir die getesteten Suchmaschinentools sowie die Konfiguration des jetzt eingesetzten regain.
Yacy
Anfangs probierten wir Yacy aus. Yacy ist eigentlich eine verteilte Suchmaschine, bei denen je eine Maschine im Verbund für einen bestimmten Teil der zu durchsuchenden Daten zuständig ist, diese indiziert und bei der Suche Ergebnisse für diesen Teil der Daten zurückgibt.
Yacy kann allerdings auch im Einzelmodus ("Robinson Modus") betrieben werden, was wir bei uns so konfigurierten.
Mit der Zeit häuften sich aber die Probleme:
- Der RAM der Maschine war mit 768MiB zu klein, als immer mehr Daten indiziert wurden.
- Das Log quoll über mit "Snippet konnte nicht geladen werden"-Meldungen.
- Yacy ist immer mal abgestürzt oder hat nicht reagiert. Einmal sahen wir auch einen Kernelfehler.
- Es war schwierig zu sehen, was indiziert wurde und was nicht, und warum nicht.
- Das Admininterface ist ziemlich überladen. Man weiss oft nicht, was die Einstellungen bedeuten und wo sie Effekt haben.
Nachdem die Such-VM mal wieder abgestürzt und nicht erreichbar war, wurde sie nach einem halben Jahr Testphase abgeschaltet und stattdessen regain ausprobiert.
regain
Nach den ganzen Problem mit Yacy kommt jetzt regain zum Einsatz.
Trotz aller noch existierenden Probleme funktioniert die Suche zufriedenstellend über alle Werkzeuge hinweg.
Ein aus meiner Sicht großer Vorteil ist, dass regain über eine Konfigurationsdateien angepasst wird. Damit hat man alle Einstellungen im Blick und kann diese auch einfach ins Backup aufnehmen.
Der Suchcomputer kommt problemlos mit 768MiB RAM aus.
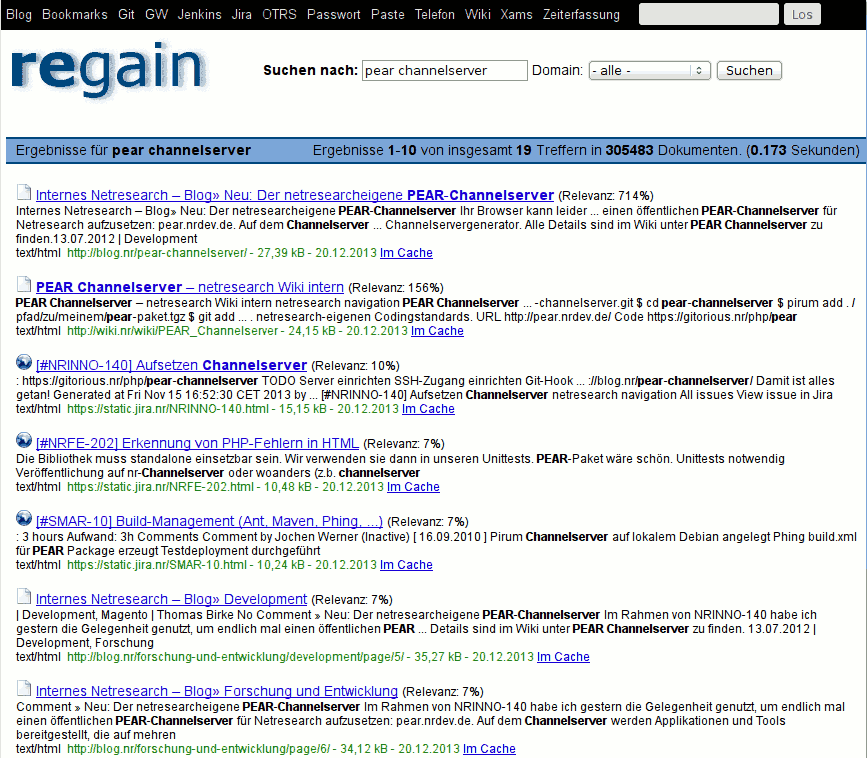
mehrere Indizes
Indizierungs- und Suchkonfiguration sind voneinander getrennt, und man kann auch unterschiedliche Suchindizes anlegen, die unterschiedlich konfiguriert sind. Die Suche kann mehrere Indizes auf einmal durchsuchen.
Wir haben zwei Indexe, einen für das Projektlaufwerk und einen für den Rest.
Während der Einrichtung der Laufwerksindizierung musste der Index immer mal gelöscht werden, wobei aber nicht alle anderen Domains reindiziert werden sollten. Hier hilft die Trennung, weil man die Indexdateien einfach löschen kann.
Das Projektlaufwerk ist ziemlich groß; die Indexgröße beträg 1.1GiB. Der Rest sind knapp 400MiB Index. Falls mal etwas kaputt geht wurden die Dateien lieber getrennt, um die Wiederherstellung zu erleichtern.
Informationen zur Konfiguration findet man im Forum.
Crawlerkonfiguration
Die Konfigurationsdateien haben wir in /etc/regain/ abgelegt. Standardmäßig sucht regain im .jar-Verzeichnis nach der Konfiguration, aber das kann man mit dem CLI-Parameter -config/etc/regain/CrawlerConfiguration.xml ändern.
Reindizierung erfolgt einmal am Tag, nachdem alle Backups durchgelaufen sind und bevor die ersten Leute auf Arbeit kommen:
$ crontab -l -u regain 00 06 * * * cd /opt/regain/runtime/crawler/ && umask 0002 && java -jar regain-crawler.jar -logConfig /etc/regain/log4j-cron.properties -config /etc/regain/CrawlerConfiguration.xml 00 07 * * * cd /opt/regain/runtime/crawler/ && umask 0002 && java -Xmx128m -jar regain-crawler.jar -logConfig /etc/regain/log4j-cron.properties -config /etc/regain/CrawlerConfiguration-projekte.xml
Die Konfiguration des Crawlers haben wir in einigen wenigen Punkten angepasst:
- <startlist> enthält alle Domains, die wir indizieren wollen
- <whitelist> enthält auch alle Domains, die wir indizieren wollen. Damit wird verhindert, dass die Suchmaschine Kundenprojektseiten indiziert.
- <blacklist> enthält für die Suchergebnisse "unnütze" URL-Präfixe:
- http://blog.nr/tag/
- http://wiki.nr/api.php
- <auxiliaryFieldList> enthält Einträge, mit denen wir die den Bereich ("Domain") der Suchergebnisse festlegen. Das erlaubt es uns, zusätzlich zum Suchfeld noch ein Dropdown mit der Einschränkung auf die Domain anzubieten.
Der Rest der Konfiguration haben wir im Ursprungszustand belassen.
<startlist> <start parse="true" index="true">http://adressbuch.nr/</start> <start parse="true" index="true">http://blog.nr/</start> <start parse="true" index="true">http://bookmarks.nr/</start> ... </startlist> <whitelist> <prefix>http://adressbuch.nr/</prefix> <prefix>http://blog.nr/</prefix> <prefix>http://bookmarks.nr/</prefix> ... </whitelist> <blacklist> <prefix>http://blog.nr/tag/</prefix> <prefix>http://blog.nr/wp-login.php</prefix> <prefix>http://wiki.nr/api.php</prefix> <prefix>http://wiki.nr/index.php</prefix> ... </blacklist> <auxiliaryFieldList> <auxiliaryField name="extension" regexGroup="1" toLowercase="true"> <regex>\.([^\.]*)$</regex> </auxiliaryField> <auxiliaryField name="location" regexGroup="1" store="false" tokenize="true"> <regex>^(.*)$</regex> </auxiliaryField> <auxiliaryField name="domain" regexGroup="1" store="false" tokenize="false"> <regex>^http://([^/:]+)/</regex> </auxiliaryField> <auxiliaryField name="domain" value="chatlogs"> <regex>^http://xmpp.nr:5290/</regex> </auxiliaryField> </auxiliaryFieldList>
In der Projektlaufwerkskonfiguration haben wir nur die Projektdateien eingestellt, den Suchindexspeicherort angepasst und die Vorschau deaktiviert (weil die > 20GiB zusätzlichen Speicherplatz bräuchte):
<startlist> <start parse="true" index="true">file:///mnt/projekte/</start> </startlist> <whitelist> <prefix name="file">file:///mnt/projekte/</prefix> </whitelist> <blacklist> <regex>.*/Thumbs.db$</regex> </blacklist> <searchIndex> <dir>/var/regain/searchindex-projekte</dir> <storeContentForPreview>false</storeContentForPreview> </searchIndex> <auxiliaryFieldList> <auxiliaryField name="domain" value="projekte"> <regex>.*</regex> </auxiliaryField> </auxiliaryFieldList>
Die tägliche Reindizierung der 300.000 Dokumente dauert etwa 45 Minuten.
Suchkonfiguration
Die Konfiguration der Suche erfolgt in /etc/regain/SearchConfiguration.xml, was von regain auch nicht gemocht wird.
Damit regain die Datei liest, muss die .war-Datei nach /var/lib/jetty/webapps/regain/ entpackt und WEB-INF/web.xml angepasst werden:
<context-param> <param-name>searchConfigFile</param-name> <param-value>../../../../../etc/regain/SearchConfiguration.xml</param-value> </context-param>
Als Applikationsserver nutzen wir Jetty, dessen Unix-Benutzer wir noch in die Gruppe regain aufnehmen mussten. Grund dafür ist, dass die Suche den neuen Index selbst aktiviert, wenn er fertig gecrawlt wurde. Das klappt nur, wenn sowohl der Crawler als auch die Suche dieselbe Gruppe haben.
In der Konfigurationsdatei haben wir ein Mapping der Projektlaufwerksdateien auf HTTP, sowie ein Mapping von HTTP auf HTTPS für sensible Daten.
Weiterhin sind dort die beiden Indizes definiert, die durchsucht werden sollen. Der Rest ist unverändert:
<indexList> <defaultSettings> <rewriteRules> <rule prefix="file:///mnt/projekte/" replacement="https://projekte.nr/"/> <rule prefix="http://static.jira.nr/" replacement="https://static.jira.nr/"/> </rewriteRules> </defaultSettings> <index name="main" default="true" isparent="true"> <dir>/var/regain/searchindex</dir> </index> <index name="projekte" default="true"> <dir>/var/regain/searchindex-projekte</dir> </index> </indexList>
Zusätzlich haben wir noch den Domainfilter konfiguriert, und zwar in Dateien der entpackten regain.war: search_form.jsp, searchinput.jsp und advancedsearch.jsp bekommen:
<label style="font-weight: normal">Domain: <search:input_fieldlist field="domain" allMsg="{msg:allItem}"/> </label>
bzw.
<tr> <td>Domain:</td> <td><search:input_fieldlist field="domain" allMsg="{msg:allItem}"/></td> </tr>
Probleme
Auch mit regain haben wir noch unsere Probleme. Hier eine wahrscheinlich vollständige Liste:
- regain (oder jetty) gibt alte Indexdateien nicht frei (bzw. schliesst sie nicht). Das führt dazu, dass der freie Plattenplatz schrumpft, obwohl die alten Indizes gelöscht werden. Wir haben das Problem umgangen, indem wir jetty einmal in der Nacht neustarten.
- regain unterstützt keine facettierte Suche, bei der man die Ergebnisse einfach per Klick weiter einschränken kann (z.B. auf die Domain, die Dateiendung oder Dateigröße).
- regain ist schwer zu debuggen. Mal einfach so eine Einstellung verändern und auf einer bisher falsch indizierten URL testen funktioniert nicht, weil es immer alles neu indizieren möchte. Der einzig mögliche Weg ist eine einzelne Konfigurationsdatei, die auf die eine URL beschränkt ist - was aber ziemlich nervig aufzusetzen ist.
- Die erste Suche am Morgen oder manchmal auch mitten am Tag dauert 10 Sekunden, während die Ergebnisse sonst innerhalb einer Sekunde ausgeliefert werden. Die Ursache ist unklar; danach geht auch alles schnell.
- Der Support ist nichtexistent. Die regain-Entwickler haben ein Forum, in dem seit einem halben Jahr aber keiner mehr antwortet.
- Keine Unterstützung für eigene SSL-Root-Zertifikate (oder welche von CAcert).
- Einige HTML-Dateien werden nicht als HTML erkannt. Hier muss noch debugged werden. XHTML-Dateien ohne Endung .html werden auch nicht als HTML erkannt, was an einer alten Bibliothek liegt.
Konfiguration der Tools
Die Suchmaschine wird im Browser benutzt, und kann am Besten auf Daten verlinken, die über HTTP erreichbar sind. Viele unserer Tools haben allerdings eine Authentifizierung, oder sind gar nicht über HTTP erreichbar.
Chatlogs
Als XMPP-Server verwenden wir prosody, der via mod_muc_log Logs schreiben und per mod_muc_log_http via HTTP verfügbar machen kann.
regain kann ganz einfach darauf angesetzt werden.
JIRA
Für JIRA gibt es keine automatische Authentifizierung, deshalb exportieren wir alle Projekte und Fälle mit jira-export in statische HTML-Dateien. Diese können problemlos indiziert werden.
Die statischen Dateien können von der Suchmaschine über HTTP ohne Authentifizierung abgerufen werden, während alle anderen über HTTPS mit LDAP-Authentifizierung darauf zugreifen können. Das Mapping der URLs von HTTP auf HTTPS erfolgt in der Suchkonfiguration.
Ein Problem mit JIRA ist, dass man entweder viel zu viele Projekte angezeigt bekommt oder - wenn man die alten der Übersichtlichkeit halber deaktiviert - nicht mehr auf diese zugreifen kann.
Der statische Jira-Export soll allerdings alle Fälle und Projekte indizieren, weshalb wir einen eigenen "suche"-Benutzer angelegt haben, der nach Abschluss eines Projekts als einziger noch Zugriff auf das Projekt hat.
Damit wird man im täglichen Ablauf nicht von toten Projekten gestört, hat über die Suchmaschine aber immer noch Zugriff auf die Fälle.
LDAP-Adressbuch
Unser Adressbuch ist nur via LDAP erreichbar - ein Protokoll, das regain nicht versteht. Also haben wir einen LDAP-zu-HTML-Konverter gebaut, der jede Nacht den aktuellen Stand in HTML exportiert. Die 11.000 HTML-Dateien werden problemlos indiziert.
Mediawiki
Normale Benutzer müssen sich im Wiki authentifizieren, die Suchmaschine nicht: Mit Hilfe der Extension IPAuth wird sie automatisch angemeldet.
Projektlaufwerk
Das Projektlaufwerk ist per CIFS auf der Suchmaschine gemountet und wird einfach von regain indiziert. Damit die Dateien in den Ergebnissen angeklickt werden können, werden sie zusätzlich noch über HTTPS freigegeben.
Die Verzeichniskonfiguration im Apache-VHost sieht so aus:
<Directory /mnt/projekte/> Options Indexes FollowSymLinks MultiViews IndexOptions +FoldersFirst IndexOptions +IgnoreCase IndexOptions +IgnoreClient IndexOptions +SuppressDescription IndexOptions +SuppressHTMLPreamble IndexOptions +VersionSort IndexOptions +XHTML AllowOverride None Satisfy any Deny from all Allow from 127.0.0.1 AuthName "Windows-Benutzerdaten" AuthType Basic AuthBasicProvider ldap AuthLDAPBindDN "readuser" AuthLDAPBindPassword "readuser" AuthLDAPURL "ldap://192.168.1.4/OU=Benutzer,OU=Netresearch,DC=netresearch,DC=nr?samAccountName?" Require ldap-attribute memberOf="CN=Netresearch-Entwicklung,OU=Gruppen,OU=Netresearch,DC=netresearch,DC=nr" Require ldap-attribute memberOf="CN=Netresearch - Marketing,OU=Gruppen,OU=Netresearch,DC=netresearch,DC=nr" </Directory>
Das Mapping von lokalen Dateinamen auf die HTTP-Dateinamen erfolgt wieder in der Suchkonfiguration.
Fazit
Das Aufsetzen der eigenen Suchmaschine hat zwar Zeit und Nerven gekostet, ist im täglichen Betrieb aber nicht mehr wegzudenken. regain erfüllt seine Aufgabe gut.
Die Möglichkeit, mit einer einzigen Suchanfrage alle betriebsinternen Daten zu durchsuchen, ist überwältigend.