I wrote a search engine to be able to search my blog, website and all linked pages. It's running at search.cweiske.de using PHP, Elasticsearch and Gearman.
When looking for a way to add search functionality to my blog, I found a few hosted search providers and some existing software but none that matched my taste. I had used regain before, but found too many problems.
So I had to do it all myself, again.
Features
My head already contained a list of must-have features:
Crawler
- Crawl + index URLs like a "real" search engine (as opposed to knowing the Wordpress database structure and searching in that)
- Support for multiple domains
- Indexing of all URLs that are linked from my own pages
- Author extraction (meta tags, microformats)
- Image EXIF + PDF text parsing
Search interface
- Must be fast
- Rank matches in title higher than in headline, headline higher than text
- Excerpt display with search term highlighting
- Sort by relevance and date
- Facets to drill down: File type, language, domain, tag/keyword
- Time filter: Modification date before/after/at a given date
Implementation
I use PDO for SQL database access (subscriptions), Net_URL2 for URL parsing/resolving and HTTP_Request2 for doing HTTP requests. No frameworks, only libraries.
As of version 0.2.1, phinde consists of 1800 lines of PHP code and 400 lines of HTML/Twig.
Index storage
Because I wanted to rank headlines higher than normal text, MySQL full text search could not be used. From phorkie's development I knew that Elasticsearch supports field boosting and settled with that.
I made a schema that contained individual fields for title, each of the headline types (h1-h6), the text and tags/keywords. The fields each got a different boost that determines their priority in search result ranking.
My blog+website index contains 3.600 documents and takes 34 MiB (mostly "normal" HTML pages). The indieweb chat search instance indexes 900.000 documents, with a size of 550 MiB (tiny documents, each a single chat log line).
Elasticsearch works well except when there are schema changes, which often happens during development. I found it easier to throw away all data after making changes to the schema, because migrating a schema is too much work. This might be different when you have a couple of million documents in ES - but for me it's easier to let half a dozen worker processes re-crawl everything, than to implement schema migration scripts.
Crawling
Crawling the web is a prime example for parallelizing.
When a URL is fetched, the script extracts all linked URLs and determines if they should be followed. Each URL is then put in the job queue, together with information if it shall be crawled and/or indexed.
phinde uses Gearman as queue system. It allows me to spin up as many worker instances as I need, more instances meaning faster crawling + indexing.
The phinde-worker script is tiny; it only listens for incoming jobs and then starts a process script that does the actual work. This frees me from complicated error and exception handling, allows updating the processor without restarting the worker and makes development easy because I can run the processor from command line, just as the worker does.
Indexing
At first I had two different job queues: One for crawling and one for indexing. Bugs in the crawler script would not influence the indexer and vice versa.
This allowed me to crawl many URLs quickly without the indexing overhead, but also meant I had to fetch each URL twice.
Splitting crawling and indexing also means that the code needs to handle crawled-but-not-indexed and indexed-but-not-crawled cases. I originally did not handle this, which broke data integrity a couple of times.
Now the process script handles both crawling and indexing. This means only one HTTP request, and less code because I don't have to handle different processing states when updating the Elasticsearch documents.
The indexer itself fetches the HTML and then throws away all navigation, header and footer areas. Only the content as indicated by the microformats 2 e-content class is used if it's available.
Then headings, page title, text, keywords/tags and author information are extracted and stored.
The Elasticsearch head plugin is very useful for inspecting the index.
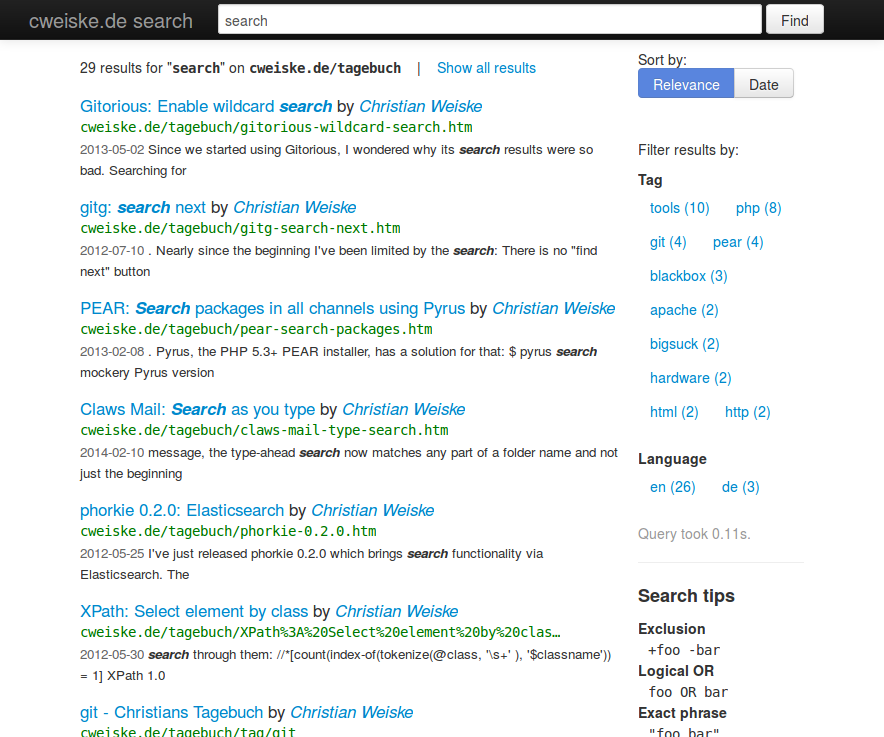
Search interface
I used bootstrap for CSS because I'm bad at layouting and Twig as templating engine because it has a nice syntax.
The home page only has a search slot and not much more, the search result page shows result document title, excerpt of the content that contains the search terms as well as the author.
On the right side sort buttons and facet filters are shown, always depending on the actual result set. Elasticsearch's aggregation feature makes that easy.
Despite the size of the chat log corpus with 900k documents, querying Elasticsearch only takes milliseconds.
I took special care of the pager and will publish a blog post with the full details of the design considerations.

WebSub
Whenever a blog post is published, the search engine needs to index it. At first I triggered it manually, then I had a cronjob that checked the my blog's atom feed every hour. None of them is ideal.
Luckily we have WebSub (formerly known as PubSubHubbub), which defines a protocol for notifications on the web. My blog already sends out notifications to interested parties via my hub at phubb.cweiske.de, which means that feed readers with WebSub support already get instantly notified about new posts.
I decided to build WebSub subscriptions into phinde, and today blog posts get indexed immediately when my blog sends out update notifications.
Current status
Since 2016-02, every page on my blog has a small search box. It takes you to search.cweiske.de with the site-specific filter set to cweiske.de/tagebuch/. It provides a button to remove the site-specific filter, which then queries all indexed pages.
Since 2016-11 a second instance is running at indiechat.search.cweiske.de. It has a corpus of ~900.000 documents and lets you search every line ever posted in the indieweb IRC channels.
I'm very pleased with the results, given that the effort it took to implement it was small - thanks to the awesome libraries and Elasticsearch, which does all the hard storage + search work.
Source code
phinde is licensed under the AGPL v3 or later and is available at git.cweiske.de/phinde.git and mirrored at github.